Kube-APIserver Explained

The kube-apiserver is the central gateway of the Kubernetes control plane, exposing the Kubernetes API and managing communication between users, components, and the etcd database.
Simply put, whenever you run a command with kubectl or send a REST request, it first passes through the kube-apiserver.
How kube-apiserver Works
Here’s the simplified workflow when you interact with a Kubernetes cluster:
You run a kubectl command.
The kube-apiserver receives the request.
It authenticates and validates the request.
It retrieves or updates data in etcd.
The response is sent back to you.
If you prefer not to use
kubectl, you can interact with kube-apiserver directly using cURL POST requests to its API endpoints.
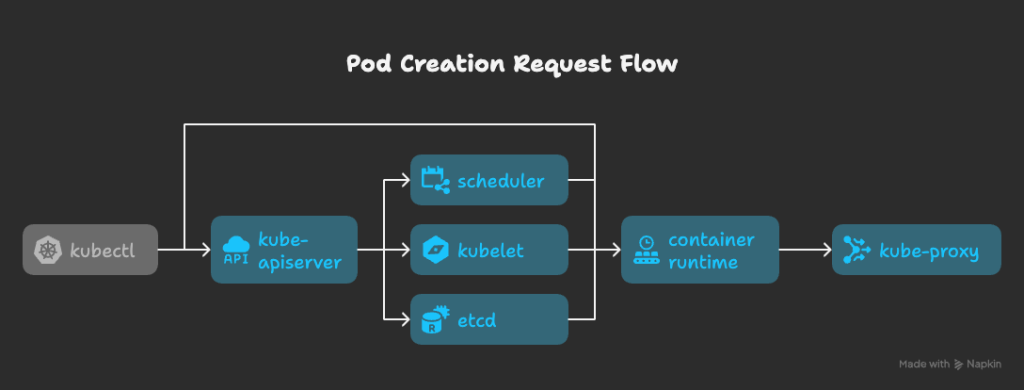
Pod Creation Request Flow
The journey of a pod creation request illustrates how the kube-apiserver integrates with the entire cluster:
kubectl→ kube-apiserverkube-apiserver → etcd (store request)
etcd → kube-apiserver
kube-apiserver → scheduler
scheduler → kube-apiserver
kube-apiserver → kubelet (on worker node)
kubelet → container runtime (e.g., Docker, containerd)
container runtime → kube-proxy (assign IP & networking)
kubelet → kube-apiserver → etcd (final state saved)
This flow ensures all cluster objects are validated and persisted before workloads start. object creation, update, or deletion is secure, validated, and stored consistently in etcd.
Key Roles of kube-apiserver
Acts as the single entry point to the cluster
Handles authentication and authorization
Provides REST API endpoints
Is the only component that directly interacts with etcd
Frequently Asked Questions (FAQs) for Kube-APIserver
Is kube-apiserver the same as Kubernetes API?
Not exactly. The Kubernetes API is the interface, while kube-apiserver is the component that implements and exposes it.
Can I bypass kube-apiserver to access etcd directly?
It’s strongly discouraged. kube-apiserver ensures security, consistency, and validation before storing data in etcd. Direct etcd access risks corrupting the cluster state.
How does kube-apiserver handle high loads?
In large clusters, multiple kube-apiserver instances can run behind a load balancer, ensuring scalability and high availability.
Does kube-apiserver store data?
No, it doesn’t store data itself. All persistent cluster state is stored in etcd, with kube-apiserver acting as the mediator.
What happens if kube-apiserver goes down?
Your cluster won’t accept new API requests (like creating pods), but existing workloads will continue to run since kubelets and container runtimes operate independently.
How can I interact with kube-apiserver without kubectl?
You can use curl or other HTTP clients to send direct REST API calls to kube-apiserver.
[Video] Kube-APIserver Explained
https://youtu.be/JNe1gzVCMIo
Conclusion
The kube-apiserver is the heart of the Kubernetes control plane, ensuring that every interaction between users, system components, and etcd is secure, validated, and consistent. From pod creation to cluster management, nothing happens in Kubernetes without passing through the kube-apiserver.
By understanding how kube-apiserver works and its request flow, you gain deeper insight into Kubernetes’ inner workings and can troubleshoot issues more effectively.
For an official deep dive, check out the Kubernetes API Server Documentation.